
CLUES reads every
document so you
don't have to.
CLUES is an AI system that reads massive document archives, maps connections between entities, and surfaces answers with direct citations to the source material.
Try CluesScroll to explore
- NLP
- natural language queries
- NER
- named entity recognition

- RAG
- retrieval-augmented generation
- Cited
- every answer links to source
Clues capabilities
Use cases
Legal discovery
Cross-reference depositions, surface relevant case documents, reconstruct timelines from scattered filings.
Investigative journalism
Query leaked archives, FOI releases, and public filings. Find the connection your reporting needs.
Compliance & audit
Scan internal records for regulatory red flags, policy violations, and audit trail gaps.
Research & intelligence
Analyze large-scale datasets for academic research, due diligence, or open-source intelligence.
What Clues does
Under the hood

Document ingestion
Feed CLUES any document set: PDFs, court filings, contracts, emails. The system parses, indexes, and builds a semantic understanding of every page.
AI synthesis
Ask a question, get a synthesized answer, not a list of links. Every response cites the exact source document and page.
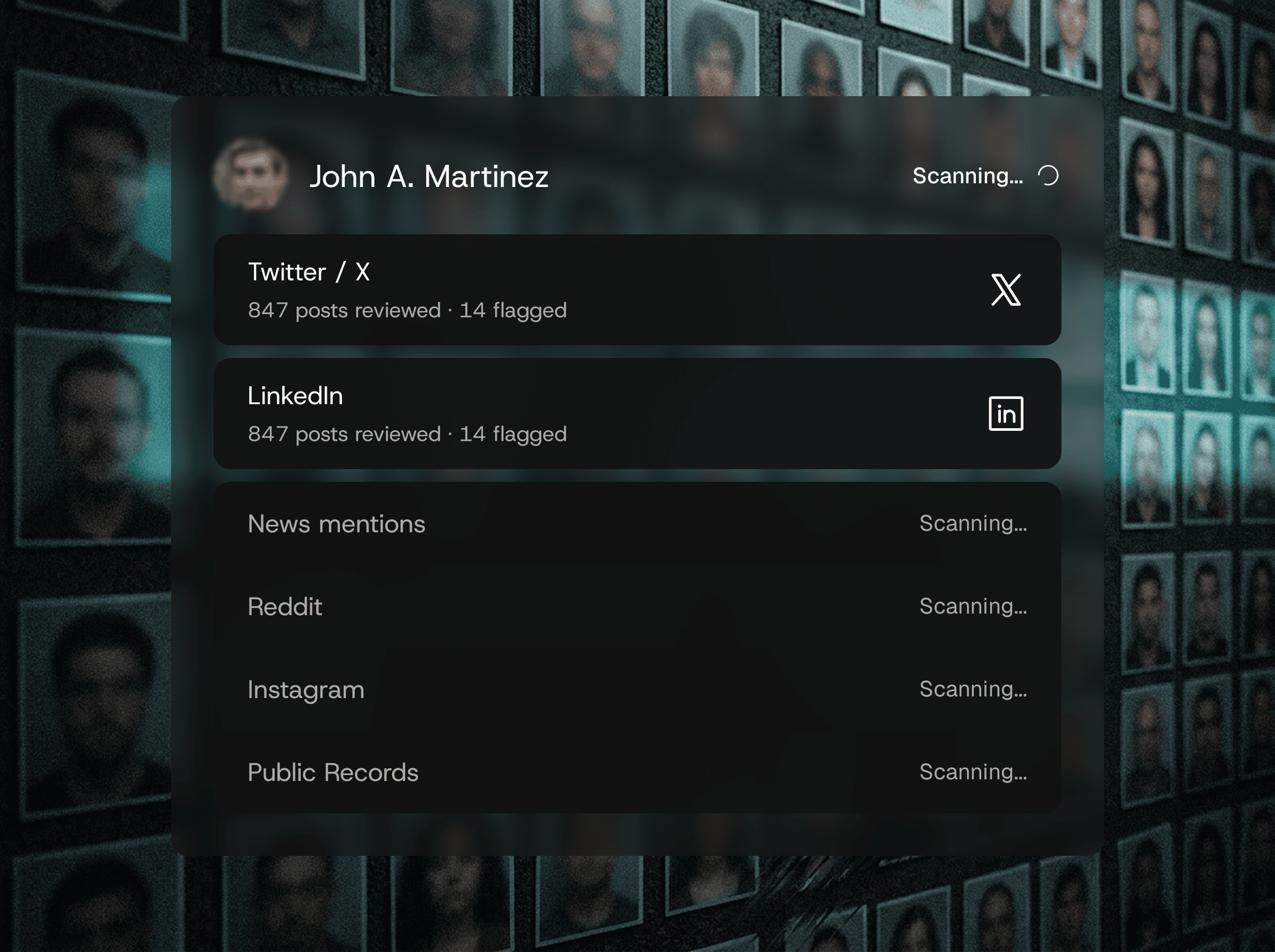
Entity extraction
CLUES uses NER and relationship modeling to automatically identify people, organizations, and how they connect across the dataset.
FAQ
Common questions about CLUES.
What kind of documents can CLUES analyze?
CLUES works with any large document set — court filings, depositions, contracts, FOI releases, leaked archives, and public records. If it can be converted to text, CLUES can read it.
How does CLUES find answers in millions of pages?
CLUES uses a combination of natural language processing, named entity recognition, and retrieval-augmented generation. You ask a question in plain English. CLUES searches the full archive, synthesizes relevant passages, and returns a cited answer, not a list of links.
Can CLUES be used on private or confidential document sets?
Yes. CLUES can be deployed on private document archives. Contact our team to discuss enterprise deployment options and data handling requirements.
Does CLUES make conclusions or just surface information?
CLUES surfaces relevant documents and connections with direct source citations. Your team interprets the findings and draws conclusions. CLUES does not make determinations or judgments.
How are answers verified?
Every answer includes a direct citation to the source document and page. Your team can review the original source independently at any time.
Is the Epstein Files demo the only available dataset?
The Epstein Files is our public demonstration dataset. CLUES is designed to work on any large document archive. Book a call to discuss your specific dataset and use case.
See it working.
Right now.
The Epstein Files (891K+ pages of court documents) is our public demo. Try it live, or book a call to discuss your own dataset.
Try Clues